


[2023 Annual Guide] Web3 Data Tools
[2023 Annual Guide] Web3 Data Tools
Covering all the top data tools and how they're used from a data analysts perspective.

Want to join an onchain data community? I’ve created an NFT passport and quest system that any analyst can participate in.
🔍 Learn about the Bytexplorers, then mint your passport and join in

It’s been another year, albeit feels like a decade has passed! I recommend reading my 2022 guide first since most concepts are still contextually relevant. This year’s guide will cover just web3 data tooling, specifically in the context of data analytics.
The 2024 annual guide is out now too, if you want a more up to date landscape.
If you loved this article, you can show appreciation by collecting an edition of the “[2023] Web3 Data Tools: Utility Stack” NFT on Zora. 💓
On Data Tooling:
Everyone - whether they started as an indexer, explorer, scorer, query engine, etc. - now contains raw and aggregated queries with some API support. Because of this, I’ve stopped thinking about data tooling as a technical stack and instead as a utility stack.
This means all tools have some “use cases” along the analyst journey they fit into, creating a stack. I’ve mapped out the top tools I’m aware of in the diagram below! I’ll then concisely explain each tool in the context of the utility layer
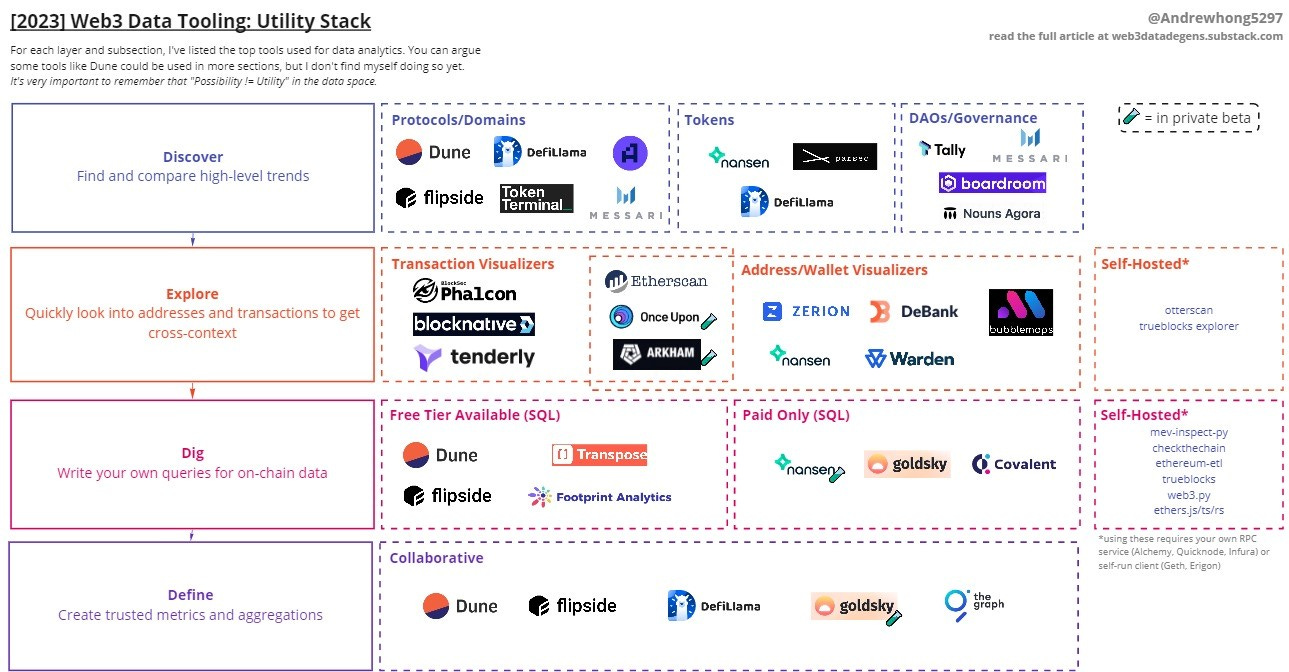
A couple of disclaimers:
I work full-time at Dune.
🧪 means this part of the product is still in private beta right now. So you’ll need to request the team for access.
I chose not to include purely API products in this analysis because everyone has an API now with some mix of raw/decoded/aggregated data. I can’t reasonably cover them all here. If you want to learn where some enhanced APIs are going, check out this article.
Query-to-dashboard providers like Dune could support all sections here. However, query-based dashboards don’t compare to the UX (feature loop and low latency) of dedicated apps for certain sections yet, so I haven’t included them.
Discover: find and compare high-level trends
All journeys begin somewhere. I use a couple of the tools in this section to examine a topic and spot trends I want to explore further. Finding the right questions to analyze is one of the hardest parts of web3, and these tools make it much easier.
Over the last year, we’ve really evolved from purely on-chain data dashboards or simple ranking tables (rip defipulse 🙏) to full-blown discovery products with enhanced search and metadata. It’s becoming easier than ever for anyone to sleuth and share the data - citizen journalism is alive and well!
💡 OurNetwork and Dune Digest are two of the best news aggregators for on-chain analytics alpha. A lot of my discovery journeys to various tools in this section start with their articles.
Protocols/Domains: To get a sense of how a protocol (or domain) is performing according to a large variety of metrics, you can reference one of these tools.
Dune can be used for finding granular dashboards for erc20s, NFTs, staking, airdrops, auctions, and much more. There is a native search feature with rankings for dashboards, wizards, and queries.
Flipside can be used for discovering data science writeups and research like liquidity pools PnL, wallet rankings, and more. They are currently beta-testing newer dashboard functionalities.
DefiLlama has high-level trends on TVL, volumes, and yields. You can find some top examples in their 2022 year in review.
Messari protocol/pool board is a great alternative to DefiLlama and is growing quickly.
Token Terminal makes traditional analysis with revenues, earnings, and fees easy for protocols (dapps) or chains.
Artemis has the best charts for dev/social activity by chain, and includes overview chain metrics. They integrate well with google sheets.
Tokens: while you can use more bespoke query dashboards like the ones linked earlier to dive into tokens, you’ll likely need a more optimized product interface to make the discovery and comparison process faster and easier.
Nansen token god mode and token (defi/NFT) paradise provides insight into distributions, transactions, and wallet trends.
DefiLlama allows you to analyze token pairs for volumes and liquidity depth closely.
Parsec features Bloomberg-style analysis of tokens with a customizable terminal.
DAOs/Governance: Governance is increasingly important to track trends in, as protocol changes/updates become more frequent and treasuries need to be invested or spent.
Messari: gives insights to proposals by tagging discussions, importance, governance processes, and subdaos in their governance explorer.
Tally: voting power over time is a great starting overview of a DAO, and they have a filter-by-chain feature for finding DAOs.
Boardroom: has a nice filterable feed of all DAO proposals, although I wish there were more parameters I could filter by (i.e. proposals with a value of more than $20k only).
Agora: Right now this exists only for Nouns, but it’s great for understanding voter profiles and delegate objectives.
Explore: quickly look into addresses and transactions to get cross-context
Once you’ve found some trend that’s interesting, you likely want to figure out what common transactions look like and what wallets/addresses are behind all the transactions.
This is the step where you go wide to ensure you aren’t missing any contextual clues that will aid your analysis - and the step where you end up with 20 different tabs open.
Transaction Visualizers: Transactions can be anything from a simple ETH transfer to a slightly more complex leveraged curve stETH/ETH vault. There are transaction, trace, log, contract code, and state data that you usually need to jump through.
Blocksec/Phalcon is great for studying traces and logs within a transaction. They clearly state the order in which all the internal calls and events were emitted. Their latest update added code snippets and balance flow graphs to the tool.
Tenderly multi-chain explorer contains the fastest trace <> code snippet sleuthing, on top of other features. Has the smoothest UX/UI of all the tools, though it could do better with event log tracing and code snippets.
Blocknative is a specialty explorer for the mempool (transaction queue). You can live-listen for transactions submitted to any contract here.
Address/Wallet Visualizers: For these, ease of quickly searching, cross-analyzing, combining, and sharing wallet balances and activity was key. While there are many more “portfolio” style apps like zapper.fi and rotki, those are not conducive to data analytics work and were not directly included.
Nansen has beefed-up labels, and a wallet profiler that pairs well with their token analysis pages.
Zerion and Debank are the best free alternatives to Nansen when it comes to analyzing a bundle of wallets across multiple chains.
Warden allows defi-specific analysis of wallets (liquidation, borrows, etc) in an easily searchable format. They support Aave and soon Euler, Notional, and Compound. I’m guessing this kind of tooling will need its own section next year, as it starts a wave of heavy defi analytics explorers.
Bubblemaps helps identify interesting wallet clusters and connections once you have some token in mind.
Mixed (Transaction + Address/Wallet): These are all-in-one solutions for explorations. This will become a more crowded space that will give birth to some of the most powerful generalized products in the space - the next Google likely starts here.
Etherscan is good for getting quick overviews of a single address. I commonly use it for labels and quickly check balances and historical transfers of specific tokens (for a given wallet). They also have the most basic but digestible transaction overviews.
🧪 Onceupon.gg is the analysts’ dream. They support mini-windows in an infinite horizontal scroll and quick filtering of all transactions by methods and sources (including traces) in the context of specific tokens and entities. Every transaction is labeled and described in a human-readable manner before you even click into it. The wallet and window groupings can be easily shared and digested. The cherry on top is all addresses have a “neighbors” tab for quickly identifying top counterparties, with a graph network visualization to supplement your analysis.
🧪 Arkham is the most focused network and counterparty analysis tool. You can easily check counterparties/exchanges and balances between individuals/groups and easily breaks down transfer inflows/outflows by the transaction. Their graph network tool makes zachxbt style sleuthing easier than ever - you can easily adjust the timescale to see relationships over certain periods of time for specific wallets.
Self-Hosted: These options allow you to run an open-source block explorer locally, and are also mixed solutions.
Otterscan: basic feature parity with etherscan (roughly).
Trueblocks Explorer: fastest account history scraper out there (probably). The core project is in the next section.
Dig: write your own queries for on-chain data
All SQL engines are cloud-based, so you can use an in-browser IDE to query against raw and aggregated data (like nft.trades/dex.trades). These also allow for definition of great tables such as NFT wash trading filters.
The best protocol, community, and token analytics start here! Some engines have more specialty tables, which I will call out.
Free Tier Available (SQL): These engines can be accessed for free.
Transpose (25-second free limit, 10-minute extended max on top tier plan).
Flipside (15-minute free limit, no plans). The only one with storage/state tables right now, courtesy of TokenFlow.
Footprint (20-minute free limit, paid plans to scale compute). The only one I’ve seen with gamefi focused aggregations.
Dune (30-minute free limit, paid plans to scale compute). The only one that has decoded tables, so you don’t have to mess with raw hex/bytea conversions, function/topic signature filtering, or proxy/factory patterns.
Paid Only (SQL): These engines can only be accessed if you’re on a paid plan and get approved access.
🧪 Nansen is currently in beta with their new query engine. You can finally query their entity/address tagging tables!
Goldsky allows migration of subgraphs from theGraph (or creations of new ones) to their hosted service. You can combine subgraphs easily, solving for a big drawback to theGraph (albeit losing decentralization).
Covalent Increment has a single giant table all raw data can be queried from, and more recently has started adding aggregated data.
Self-Hosted: These are all code packages that allow you to quickly get raw, decoded, and aggregated data (with some RPC provider for a given chain). The benefit is that if you run a more efficient client (specifically Erigon), you can explore more data more quickly. Note that Erigon takes a week to sync and > 2TB of space on your drive; it may be faster in the future.
Python:
web3.py: one of the first packages for easily working with contract ABIs and node providers (clients) on Ethereum.
ethereum-etl: used by Nansen and google Bigquery for chain ingestion of specific block ranges. Can export to different databases or file types easily.
checkthechain: the only package with domain aggregations (like uniswap pools) on top of basic functionalities from web3.py. Custom-built for data scientists.
Ape used to be like this before becoming more of a hardhat-for-vyper solution.
mev-inspect-py: query for MEV data by block (i.e. miner payments/profits, swaps, arbitrage, etc). This flashbots data can also be found in Dune.
Golang
trueblocks-core: this tool makes it extremely fast to get transaction histories for any address. visualized in their explorer above.
Javascript/Typescript:
web3.js: the original web3 scripts package. Many methods/patterns from here are considered too verbose now compared to ethers.
ethers.js/ts: the more efficient/streamlined web3 scripts package, used extensively in frontends and smart contracts testing suites like truffle and hardhat.
Rust:
ethers-rs: created mainly to work with foundry I believe (like ethers.js <> hardhat).
Define: create trusted metrics and aggregations
Raw data is great, but to get to better metrics, you need to be able to standardize and aggregate data across contracts of different protocols. Once you have aggregations, you can create new metrics and labels that enhance everyone's analysis.
This layer of the community has the deepest combination of domain, technical, and contextual knowledge of web3.
Collaborative: All defined views are open source, and you can contribute your own code/collaborate with other analysts.
Dune allows for the creation of any of the models you need, where all chains are in one repo. There have been 300 contributors (mix of community + team members).
Flipside allows for the creation of any of the models you need, where each chain gets its own repo.
DefiLlama allows any contribution to a predefined set of metrics and is typically built off of subgraphs.
theGraph allows anyone to create a graphQL schema and mapping, limited to a specific network and usually one protocol at a time (i.e. defined contracts). Messari builds on them in a more organized way (i.e. like a Dune/Flipside/DefiLlama repo).
🧪 Goldsky is basically theGraph but only for private/paying customers, and written in SQL.
There are some query providers from the last section who have defined their own aggregations, but they aren’t open source and you can’t add to them yourself.
Looking Forward:
All around, web3 data tooling is becoming cleaner, more trusted, more social, and more collaborative. The infra is evolving so that we can all query and define better metrics faster, improving what we can discover and explore in the product. The whole ecosystem acts as one big flywheel, and this small community ultimately builds together to make the data flow. I can’t stress enough that web3 data is the social by nature!
I’m very excited to see where we get to by next year, and I hope to bring together as many new faces as possible. If you’re building a product I didn’t cover here but you’d like to showcase and get feedback on, please DM me anytime. If you feel your product was misrepresented or there is a better key feature to highlight, also reach out, and I can consider edits.
This was just the first part of my 2023 guide. The other parts will be much more targeted to analysts specifically and will be much more technical.
If you liked this article and learned something, I’d love it if you shared this article on Twitter or forwarded it to a friend 🙂
If you loved this article, you can show appreciation by collecting an edition of the “[2023] Web3 Data Tools: Utility Stack” NFT on Zora. 💓
